




Key Findings on AI Discretion
-
AI lacks human discretion, often revealing sensitive insights across systems, not by violating permissions, but by inferring patterns users weren’t meant to see.
-
Traditional security models fall short because they protect files, not meaning. Modern AI requires controls at the knowledge layer to prevent unintended disclosures.
-
Knostic’s solution uses “need-to-know” logic, combining role-based knowledge flows to ensure AI shares only what a user is contextually authorized to know.
-
AI firewalls add dynamic guardrails, enabling full data access while restricting what AI can say, enhancing both performance and trust.
-
The future of secure AI lies not in restricting their access to data, but in teaching AI systems how to make informed, ethical sharing decisions based on user roles and intent.
What does AI discretion mean for enterprise data security?
In order to streamline workflows and empower workers with the right information at the right time, companies adopt AI assistants. Then they quickly face a serious challenge: oversharing. AI systems lack the human nuances of discretion. They do not understand who should or shouldn’t access sensitive data. Humans know not to share details about layoffs, acquisitions, or internal investigations with everyone. AI does not. It treats every request the same, based only on system-level permissions. This leads to what Sounil Yu, CTO and co-founder of Knostic, has dubbed the “AI oversharing problem.” According to Yu, 70% of enterprises stall in their Copilot and AI deployments because of it.
The issue isn’t just about access to files or folders. AI models can infer confidential insights from patterns, like HR meetings and equipment purchases, even without touching protected documents. This capability breaks traditional security models that only focus on file- or folder-level permissions.
On the Down the Security Rabbit Hole podcast (Episode aired March 13, 2025, titled “AI Discretion and the Oversharing Problem”), Yu shared how Knostic addresses this. Instead of locking down data, Knostic creates knowledge-layer controls. This means AI can stay smart, able to access wide datasets, but it shares only that for which the user has a true need to know.
This article explores how Knostic is redefining AI access management. It shows how we can teach machines the human concept of discretion, and build secure, intelligent enterprise AI systems.
The AI oversharing problem
AI oversharing happens when AI tools give users access to information they should not see. The AI doesn’t break a rule; it simply doesn’t understand the context. It lacks discretion. In general, AI discretion could be defined as the ability of an AI system to make context-aware decisions about what information to share, based not only on access rights but also on a user's role, intent, and need-to-know.
This problem isn’t theoretical; it’s disrupting actual deployments today. Many enterprises discover that once AI is connected to internal systems, it begins surfacing insights that users were never meant to see. These insights aren’t coming from secret files. They emerge from patterns across everyday business data. Suddenly, employees are exposed to topics far outside their roles, like executive decisions or confidential reports. This exposure poses serious compliance, privacy, and reputational risks that many technical teams fail to anticipate. As a result, security leaders are forced to pause or limit the use of AI tools, often while business units are pushing for wider adoption.
For example, someone might have access to a SharePoint folder. That folder contains strategic planning documents. A human would understand the sensitive nature of data about upcoming layoffs. But an AI assistant may surface this content automatically if it sees a pattern. It doesn't understand that knowledge is sensitive. It only knows that it is technically allowed. The same can happen with financial or M&A data. For instance, AI might correlate seemingly unrelated meeting schedules and budget updates which, taken together, suggest that a merger is happening. Even though the underlying documents are restricted, the assistant lacks the judgment to recognize the strategic implications. This creates exposure not through direct access, but through a failure to apply discretion.
This shows the flaw in relying only on access controls at the data or application level. Tools like SharePoint or internal databases support file-level security. But knowledge is not stored in just one place, and AI can infer it across systems. Without a control mechanism at the knowledge level, these systems will continue to overshare. And that breaks trust in AI inside the enterprise.
In short, traditional models fail because they secure data locations, not meaning, and AI thrives on meaning.
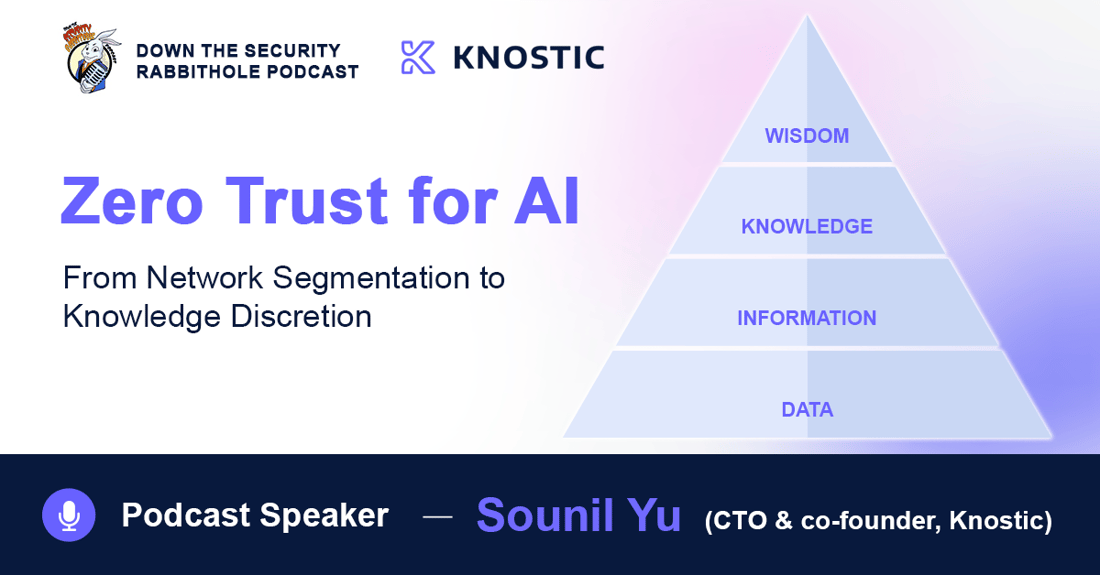
The DIKW Pyramid and its implications
To understand the oversharing issue more clearly, it's helpful to use the DIKW Pyramid, a conceptual model that shows how raw data evolves into wisdom through layers of processing and interpretation.

The DIKW Pyramid illustrates the progression from raw Data, to contextual Information, to interconnected Knowledge, and finally to actionable Wisdo
This mental model breaks down how data turns into actionable insight. At the base is Data - raw facts with no context. Above it is Information - data that has been processed or labeled. Then comes Knowledge - where relationships and meaning are added. At the top is Wisdom - judgment built on experience and context.
Traditional security models work at the lower levels. They control who can access files (data) or read reports (information). Labels like “confidential” or “internal use only” guide these controls. These layers are relatively straightforward to manage, but they fall short when it comes to AI. Sounil Yu points out an important flaw in this approach. When AI systems are restricted at the data and information levels, they often lack the broader context needed to generate meaningful responses. While the model may still function, it can’t form accurate connections or insights if it’s cut off from relevant signals across the broader data landscape. As Sounil Yu notes, limiting input too strictly undermines the very capabilities enterprises adopt AI for, accelerating insights and supporting complex decision-making.
The solution is to apply controls at the knowledge level. This means shaping what AI can share, not what it can see or infer. It allows AI to stay intelligent while still respecting boundaries. Instead of blocking access to raw data, it controls what conclusions are allowed to reach the user. This shift protects sensitive knowledge without weakening the AI. It’s a smarter approach that aligns with how people think and work. A visual of the DIKW pyramid helps illustrate the point: placing controls too low narrows the foundation and weakens the entire structure. In contrast, controls at the knowledge level keep AI both effective and secure. This is the shift modern enterprise security must make.
Why data classification alone fails
Traditional data classification systems were not designed for inference engines. Labels like “Confidential” or “Top Secret” assume the threat is direct access. If someone can’t open the document, the assumption is that the data is secure. But LLMs don’t work this way. They don’t need direct access to a specific document to provide revealing insights. Instead, LLMs draw meaning from patterns across unrelated sources. This exposes a critical limitation in traditional classification systems: even when sensitive documents are locked down, their implications can still be surfaced. For instance, recurring HR meetings, reduced equipment orders, and updated floor plans may not be labeled as sensitive. And if they are taken together, they can signal upcoming layoffs .
Trying to prevent this issue by blocking data often makes things worse. When access restrictions are too aggressive, they not only reduce AI effectiveness but also weaken transparency. For example, removing race or gender data from a dataset might seem like a way to reduce risk, but it actually makes it harder to audit the model for fairness. Without those signals, organizations cannot detect whether biased patterns are influencing outcomes. Hidden biases become harder to trace, and accountability is reduced as a result.
The answer is not to block everything. It’s to guide AI at the knowledge level. Let it see the data, but teach it what to say and where to exercise discretion. This is where traditional classification fails and why new policy layers are needed to align AI with enterprise risk.
Importance of knowledge-layer AI discretion
Knowledge-centric AI discretion is not just a feature. It marks a transformative step in how enterprises govern AI. It moves away from rigid data access controls and toward dynamic, intelligent boundaries. It mirrors how people think, based on role, context, and intent. This shift creates new opportunities but also new responsibilities for security teams.
As AI tools grow in complexity, static access rules will no longer be enough. Organizations will need adaptive guardrails that respond to changing roles and evolving tasks. This includes real-time monitoring of user interactions. If someone starts asking a series of probing questions, the system should flag it. It should detect intent even when the user avoids asking directly. This form of detection is what Sounil Yu describes as spotting “dancing around” behavior.
The long-term goal is even bigger. It’s not only about preventing improper sharing; it is about guiding AI to act with judgment. In time, we must teach AI a version of wisdom, an encoded understanding of values, ethics, and human discretion. That is what turns data into decisions. Enterprise AI is evolving fast. To keep up, security must evolve with it.
Policy-driven knowledge controls
Implementing knowledge-based controls begins with a clear separation between two core ideas:
-
Policy decision: determining what a user should or should not know
-
Policy enforcement: ensuring that the system adheres to those decisions
Most current enterprise systems focus only on enforcement, often using rigid permissions and access rules. But without a solid foundation in decision logic (understanding why and whether a user needs certain information) these controls can fall short. The result is gaps in judgment, inconsistent AI behavior, and a failure to align access with actual business context.
Traditional systems struggle because they begin with data structures and static access rights, not with “need-to-know”. As AI systems become more capable of inference, organizations need a more thoughtful, role-aware approach that governs meaning, not just data.
Implementing knowledge controls with Knostic
Knostic starts from a different premise: “What does this person, in this role, truly need to know?”
That question anchors its entire policy framework (prioritizing purpose and context over rigid data permissions).
To define intelligent access boundaries, Knostic uses knowledge flows and knowledge pings. These are simulated queries that reflect real-world role-based needs. For example:
-
Can an HR coordinator access the company’s product roadmap?
-
Should a marketing intern know next quarter’s earnings targets?
The tools help define practical and adaptive “need-to-know” policies across departments and industries.
Knostic then enforces these boundaries using not rigid blockers, but custom guardrails based on a user’s role, function, and intent. Unlike traditional DLP or DSPM tools, Knostic operates at the knowledge layer, governing what AI is allowed to say, not just what it can access or infer.
This provides several enterprise benefits:
-
Smart output controls mean AIs can be trusted with full data access
-
Fewer security blind spots
-
Fast detection of oversharing risks (less than a day)
-
Security teams shift from blockers to enablers, defining intelligent, context-aware rules that strengthen AI while supporting productivity.
What’s next?
The future of AI security is in better judgment.
As AI becomes more capable of correlation and inference, static access rules won’t be enough. Enterprises need real-time, adaptive controls that respond to changing roles, context, and intent.
Knostic’s approach aims to give AI systems a sense of human discretion, a framework for making informed, role-aware decisions about what to share. It's a shift from blocking data to guiding behavior, aligned with organizational values and risk tolerance.
Download our solution brief to learn how Knostic enables secure, role-aware AI that protects sensitive knowledge while maximizing business performance.
FAQ
Q: What is AI discretion?
A: AI discretion is the capacity of an AI system to decide what information to reveal, withhold, or transform based on context, policy, user role, and risk. It mirrors human discretion and judgment to protect confidentiality, compliance, and ethical standards while still delivering useful output.
Q: Why does AI discretion matter in enterprise environments?
A: Without a discretionary layer, generative models can overshare sensitive data or provide incomplete context. AI discretion helps organizations:
-
Reduce data-leak risk and regulatory exposure
-
Maintain trust with employees and customers
-
Align AI outputs with corporate policies, contracts, and ethics guidelines.
Q: How can organizations implement AI discretion in practice?
A: Typical approaches include:
-
Policy-aware prompt filtering: block or rewrite prompts that request restricted data.
-
Output redaction & summarization: dynamically mask sensitive fields or replace them with abstractions.
-
Role-based response scopes: tailor answers to each user’s privileges.
-
Audit & feedback loops: log every decision and continuously refine rules or fine-tunes to close gaps.


The Data Governance Gap in Enterprise AI
See why traditional controls fall short for LLMs, and learn how to build policies that keep AI compliant and secure.












![AI Data Governance Guide for Enterprise Teams [2025]](https://www.knostic.ai/hs-fs/hubfs/What-is-AI-data-governance.jpg?width=520&height=294&name=What-is-AI-data-governance.jpg)


