The Source Looked Clean. The Binary Wasn't.
29 June 2026
![]()
Prevent malicious prompts from hijacking your AI. Knostic stops leaks, fraud, and loss of reputation in real time.
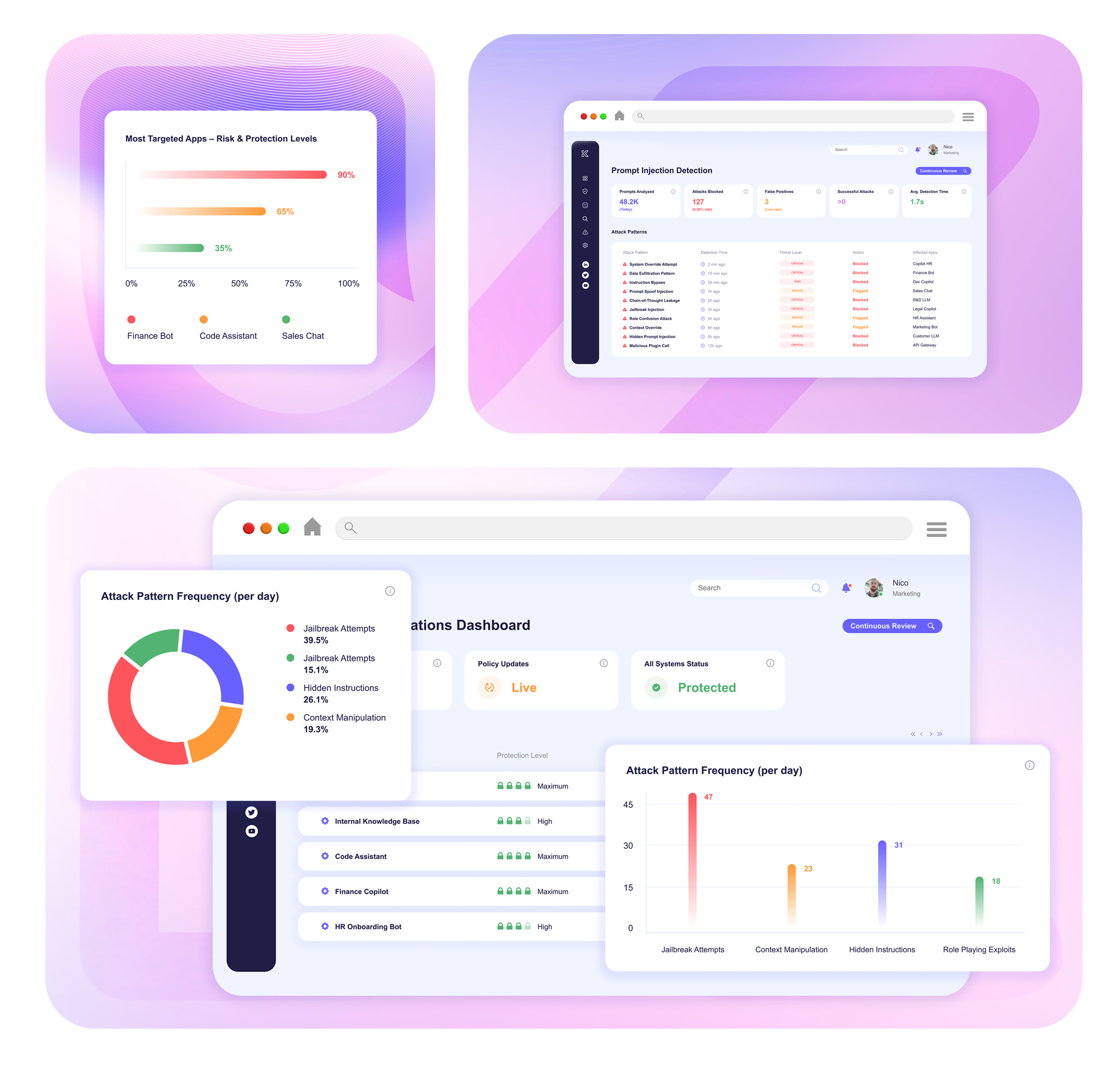

Knostic analyzes every prompt as it’s submitted, spotting manipulation attempts, like hidden instructions or jailbreaks, before they can cause harm
Suspicious inputs are automatically blocked or cleaned, preventing data exfiltration and unauthorized actions without disrupting valid queries

Knostic protects against jailbreaks, denial-of-wallet exploits, and hidden instructions, ensuring your AI applications stay secure and compliant
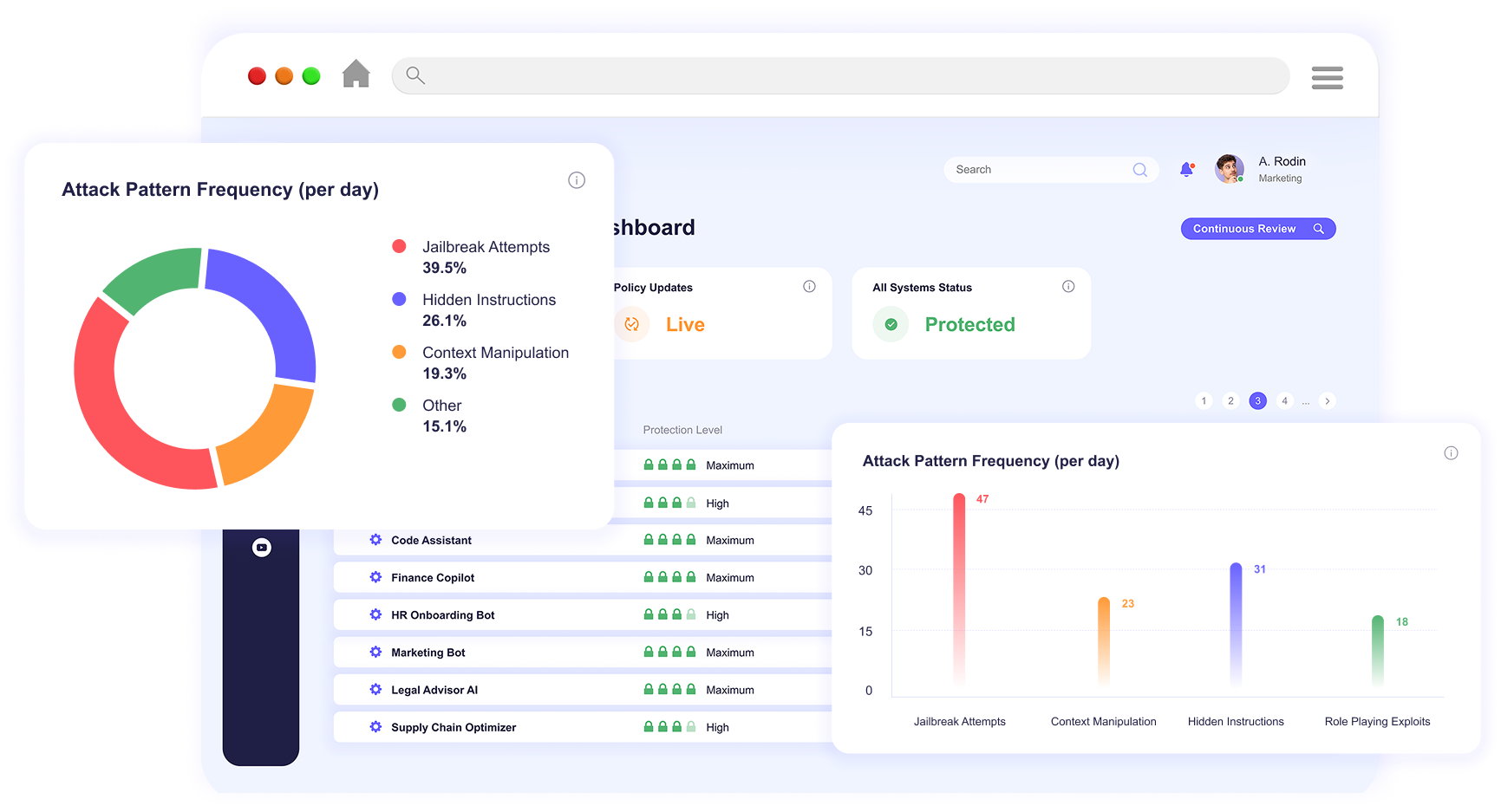
Analyze and filter prompts before they reach the model
Block or clean malicious prompts in real time
Protect against jailbreaks, hidden instructions, and denial-of-wallet attacks
Tune sensitivity and enforcement for each application or model
Maintain detailed records for incident response and compliance

Knostic keeps your AI applications secure and compliant by inspecting prompts and responses in real time, blocking malicious inputs, and defending against jailbreaks and hidden instructions.


